Advanced Daily Prediction Model for National Suicide Numbers with Social Media Data
Article information
Abstract
Objective
Suicide is a significant public health concern worldwide. Social media data have a potential role in identifying high suicide risk individuals and also in predicting suicide rate at the population level. In this study, we report an advanced daily suicide prediction model using social media data combined with economic/meteorological variables along with observed suicide data lagged by 1 week.
Methods
The social media data were drawn from weblog posts. We examined a total of 10,035 social media keywords for suicide prediction. We made predictions of national suicide numbers 7 days in advance daily for 2 years, based on a daily moving 5-year prediction modeling period.
Results
Our model predicted the likely range of daily national suicide numbers with 82.9% accuracy. Among the social media variables, words denoting economic issues and mood status showed high predictive strength. Observed number of suicides one week previously, recent celebrity suicide, and day of week followed by stock index, consumer price index, and sunlight duration 7 days before the target date were notable predictors along with the social media variables.
Conclusion
These results strengthen the case for social media data to supplement classical social/economic/climatic data in forecasting national suicide events.
INTRODUCTION
Suicide is a significant public health concern worldwide and is an important cause of death in many member countries of the Organization for Economic Co-operation and Development (OECD). Suicide accounted for over 150,000 deaths in those countries in 2013 [1]. South Korea currently has the highest OECD annual suicide rate, with nearly 30 deaths per 100,000 citizens. In addition, the suicide rate has risen steadily in South Korea over the past two decades, peaking around 2010 [2]. World Health Organization (WHO) member states have committed to addressing this global problem of suicide through comprehensive, integrated and responsive mental health and social services in community-based settings [3].
In recent decades, several clinical instruments have been developed for screening individuals at high risk of suicide [4-6]. As the social science technology advanced, interest has turned to the use of social media data for identification of suicide risk [7,8]. For instance, machine learning and natural language processing have been shown to replicate human classifications of suicide-related posts on social media [9,10]. These studies point to the potential of social media data to identify individuals at high risk of suicide. Additionally, social media data also have a potential role in suicide prediction at the population level. Jashinsky et al. [11] demonstrated a significant correlation between potential suicide-related tweets in Twitter and regional suicide rates in the United States. In our previous research, we developed a prediction model for the Korean national suicide number, using economic, meteorological, and social media data variables and it showed encouraging prediction accuracy [12]. However, our previous model needs to be refined because of its broad, 3-day prediction epochs and its limited (2-year) reference data base for the training set.
The purpose of this study is to improve the utility and accuracy of our original national suicide prediction model by modifying the design of model. We applied a serial prediction procedure which could reflect changing trends near the prediction date rather than the earlier fixed training set model [12]. We also expanded the period on which data entered in the prediction modeling are based from 2 years to 5 years, and we selected a broader range of terms from the social media content.
METHODS
General design of new prediction models
We used a serial prediction procedure to capture secular trends in the data for the 7-year time period between 1 January 2008 to 31 December 2014. Data for predictor variables were analyzed using a moving period of 5 years minus 1 week (1,818 days) that ended 7 days before the target date (t) (Figure 1). Our prediction model was applied over the final 2 years of the 7-year observation period. Thus, the first prediction model used 5-years of data from 1 January 2008 to 25 December 2012 (for simplicity we will designate this period of 1,818 days as 5 years) to predict the national suicide number for 1 January 2013 with a lag of 7 days. This prediction model advanced by 1 day, every day for 730 days to the end of the study period. The 730th prediction model, the last prediction model, used data from 31 December 2009 to 24 December 2014 to predict the national suicide number for 31 December 2014 with a lag of 7 days. Thus, each prediction was based on data for a unique 5-year period. In that unique period, the best prediction model was selected using a stepwise Akaike Information Criterion (AIC) method where the variables included in the model having the smallest AIC were selected as the good predictors [13].
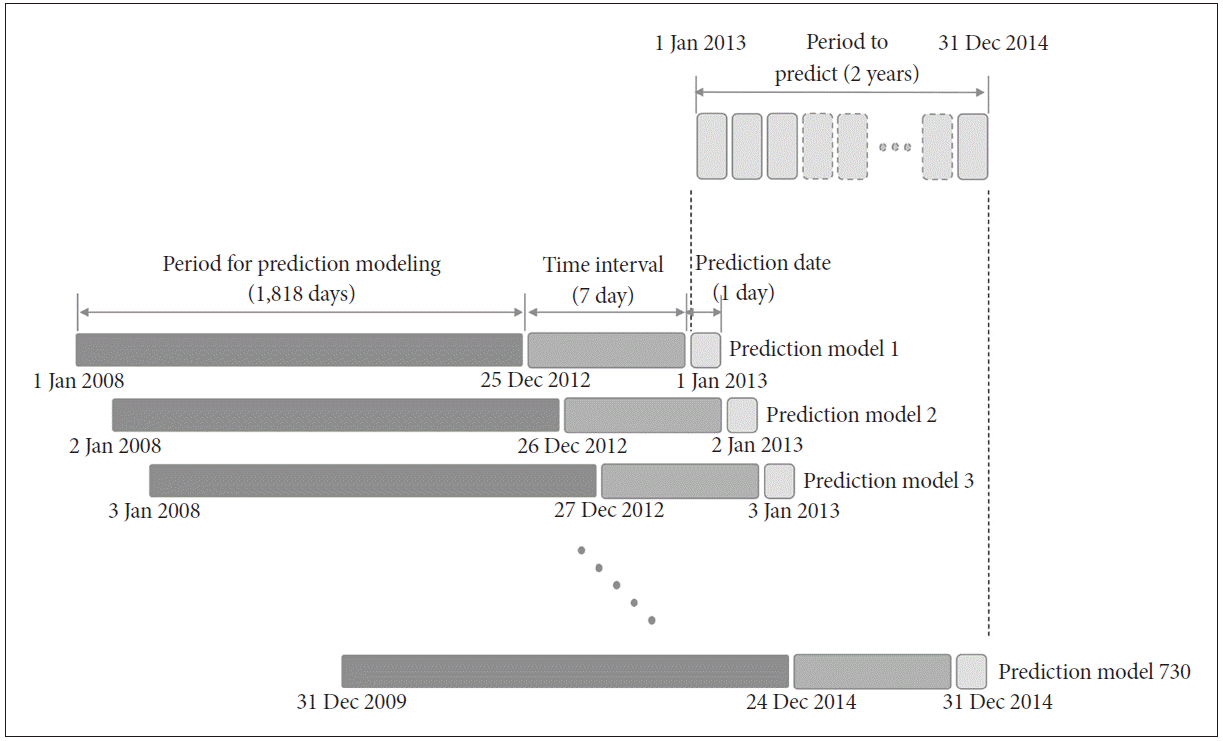
Serial prediction procedure. In this study, a total of 730 individual predictions were executed over 2 years.
Suicide data
The daily national suicide numbers in South Korea from January 1 2008 to December 31 2014 were obtained from the Korea National Statistical Office (KNSO, http://kostat.go.kr/portal/english). The data were thoroughly examined and verified by KNSO. The specific 7-year time period used in our study was chosen for the contemporaneous availability of demographic and social media data. Completed suicides were classified according to the International Classification of Diseases-10 (ICD-10) codes X60-X84, and we included suicides from all causes, including intentional self-poisoning and selfharm [14]. The observed number of suicides on day (t-7) was designated the suicide variable in the prediction models. Thus, the suicide variable in the prediction model did not consider time trends for daily suicide over the 1,818 days of the prediction period.
Social media data
We obtained social media data from Daumsoft, one of the leading social media analysis and consulting firms in South Korea [12]. The social media data were drawn from weblog posts on the Naver platform (http://section.blog.naver.com). Naver is the largest portal site for weblog services in South Korea. A set of filtering operations was applied to exclude advertisements and other noisy texts. We analyzed the weblog traffic in the period between January 1, 2008 and December 24, 2014. The weblog service processed 1,106,890,866 posts during that 7-year period. To effectively simplify and quantify the enormous amount of social media data, we recorded the measures according to their frequency of occurrence in the weblog traffic. SOCIALmetrics™, which is a social media analysis system offered by Daumsoft (http://www.daumsoft.com) [12], provides deep level keyword analysis and opinion mining for social media texts and other web documents, and the social media data were obtained using this system.
We began the social media data mining by selecting 10,035 candidate keywords. These keywords comprised 9,709 words from a sentiment word data base and 326 words that are frequently used in suicide websites. The sentiment word data base was initially constructed by repurposing the sentiment lexicon compiled by Daumsoft for its commercial text analytics service. The sentiment word data base was supplemented by sentiment words collected from previous studies on Korean sentiment words [15,16]. We also applied text mining technologies to gather complex words closely related to the seed keywords from Naver blog posts and Tweets, adapting the method used in a previous study on extending the sentiment word list [17]. The weblog count for each Korean candidate keyword was defined as the daily document frequency mentioning that word at least once. For each prediction exercise, 20 words out of the 10,035 candidate keywords were selected. The weblog counts for these 20 words had the highest statistically significant correlation coefficients over 1,818 days with the daily suicide rate on day (t) during each individual prediction period. In addition, we classified the 10,035 candidate keywords as negative, neutral and positive according to the meanings of the words, and we included these 3 classifications independently in the prediction model as social media variables. Thus, a total of 23 social media variables were considered for constructing multivariate regression models along with the other predictive variables at each prediction. An example of a multivariate regression model is shown in Table 1 and 2 lists the social media variables that were used in any of the 730 predictions. These comprised just 30 weblog counts out of the 1,035 candidate keywords, and 3 non-mutually exclusive weblog meaning categories.
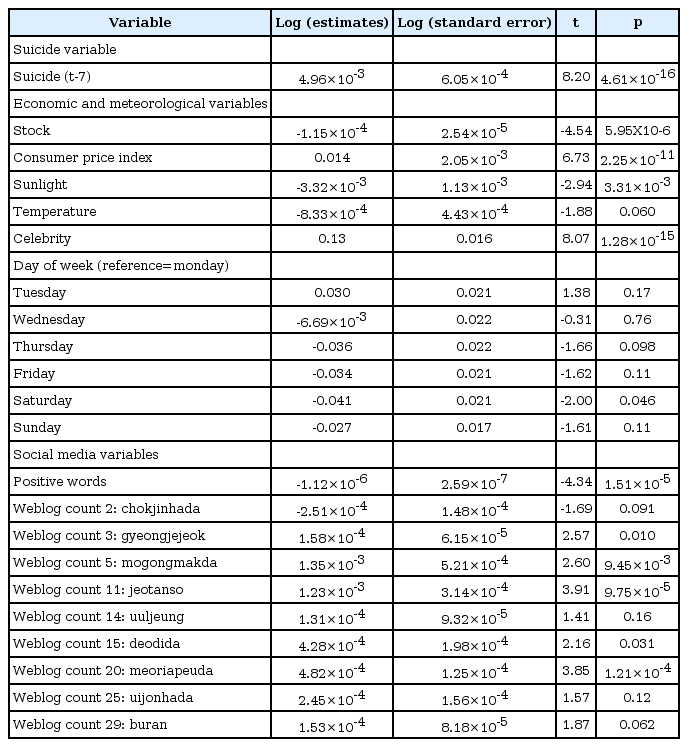
An example of the prediction model for national suicide number on 1 January 2013 by using data from 1 January 2008 to 25 December 2012
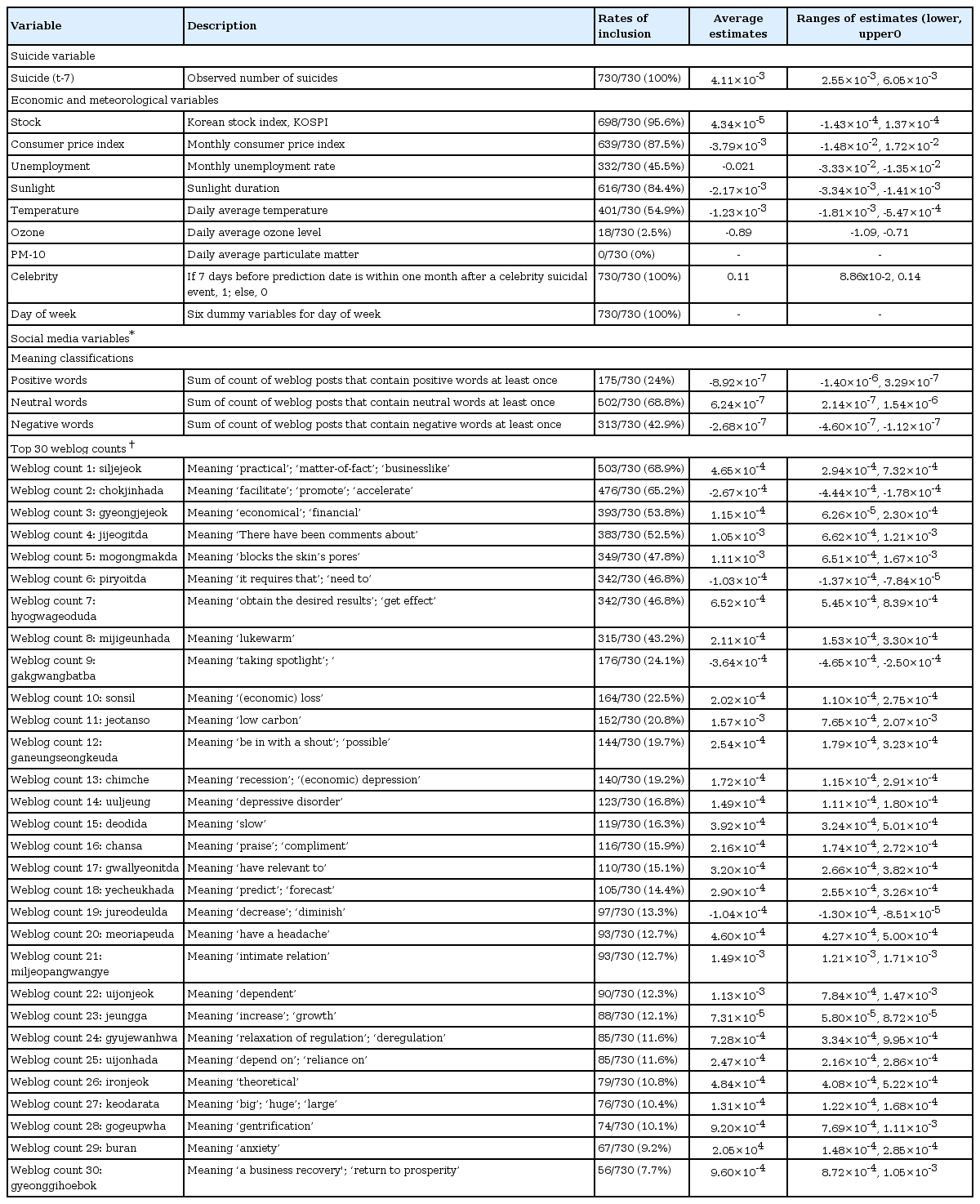
Prediction variables evaluated in 730 prediction models
Economic, meteorological, and air pollution data
Our study includes economic and meteorological variables which were identified in previous studies of suicide as important variables. The economic data [18,19], which were extracted from the KNSO, consist of 3 variables: consumer price index; unemployment rate; and stock index valuations (Korea Composite Stock Price Index, KOSPI). The meteorological data, which were obtained from the Korea Meteorological Administration (KMA, http://web.kma.go.kr/eng), consist of two variables: sunlight hours and mean daily temperature [14,20]. Two major air pollution variables [ozone and particulate matter with size of 10 μm in diameter or smaller (PM-10)] were considered based on our previous study for the association between air pollution and suicide [21]. During the study period, the observation station in Seoul was chosen for representative measurement data (http://www.airkorea.or.kr/eng/index). The 730 prediction models each used data from all 1,818 days in each unique prediction period for these variables.
Celebrity suicides
To control the influence of celebrity suicides, we considered their occurrence as a confounding variable. We regarded celebrity suicides as any suicide that received more than two weeks of exposure in news programs of the three major national television networks (KBS, MBC, and SBS) [13]. celebrity suicides met this definition during the 7 years of this study. The affected period was defined as a month (30 days) after the first report of the celebrity suicide, according to the study of Phillips [22]. Prediction dates were coded 1 when they were within this 30-day window, while all others were coded 0 on the celebrity variable. The 730 prediction models each used celebrity suicide data from all 1,818 days in each unique prediction period.
Day of week
The day of week was included as a confounding variable to control the variation in the number of suicides by date [23,24]. During the 7-year observation period, the number of suicides varied according to the day of the week. The largest number of suicides occurred on Monday (Average, 43.38; SD, 8.96), followed by Wednesday (Average, 40.87; SD, 9.00), Tuesday (Average, 40.27; SD, 7.39), Thursday (Average, 38.85; SD, 7.45), Friday (Average, 38.57; SD, 7.94), Sunday (Average, 35.65; SD, 7.48), and Saturday (Average, 34.22; SD, 7.84). The 730 prediction models each used data from all 1,818 days in each unique prediction period for this variable.
Ethics statement
Our research analyzes existing data and documents that are publicly available in a manner that does not allow individual subjects to be identified, therefore ethics approval was deemed unnecessary.
Statistical analysis
To avoid multi-collinearity problems and redundancy among the predictor variables, we selected 20 words through the Spearman’s correlation test between the daily weblog count for each of the 10,035 candidate keywords on day (t-7) and the daily suicide number 7 days later (t) across the 1,818 days of each unique modeling period. We selected the 20 words that showed the highest correlation coefficient values with suicide number on the prediction date (t), with the added requirement that each word showed p<0.05 in Spearman’s correlation test (without correction for multiple comparisons). The multivariate regression model was constructed using weblog counts of these selected words over 1,818 days, along with other predictors [observed number of suicides on day (t-7), economic and meteorological variables, and the sums of the counts of weblog posts that contain positive/neutral/negative words] over 1,818 days. The variables of the prediction models were selected stepwise based on AIC values. Following the initial period of 1,818 days in which we developed the first prediction model, we prospectively predicted national suicide number daily for 2 years from 1 January 2013 to 31 December 2014. For this operation, we used the ‘predict’ function with ‘prediction interval level’ set at 0.85 in the R software, which indicates that the observed number of national suicides is expected to fall within the upper and lower boundaries of the prediction interval with 85% probability. If the observed number fell within the prediction interval, we regarded the prediction as correct [12]. Prediction accuracy was defined as the ratio of correct predictions to total predictions. In all statistical computations, dependent variables (national suicide number on prediction date) were seasonally adjusted with a decomposition method using the ‘decomposition’ function in the Technical Trading Rules (TTR) of the R package. By this procedure, national suicide number was decomposed into seasonal and non-seasonal components, and only the non-seasonal component was included in the statistical model. Because suicide number is not normally distributed, we used natural logarithm transformation of the suicide number in the regression analysis. After the regression analysis, the predicted value of the non-seasonal component of the national suicide number on the prediction date was summed with the seasonal component on the prediction date to calculate the predicted undecomposed national suicide number. All statistical analyses were performed using the R 3.2.3 public statistics software (http://www.r-project.org).
RESULTS
Trend of annual national suicide numbers
Over the 7 years of our study, annual national suicide numbers trended upwards (suicides per 100,000 persons: 26 in 2008; 31 in 2009; 31.2 in 2010; 31.7 in 2011; 28.1 in 2012; 28.5 in 2013; and 27.3 in 2014), reflecting a general trend over 20 years preceding 2010 (Figure 2). The mean of absolute daily suicide number during this study was 38.83 (standard deviation=8.51) with a range from 16 to 72.
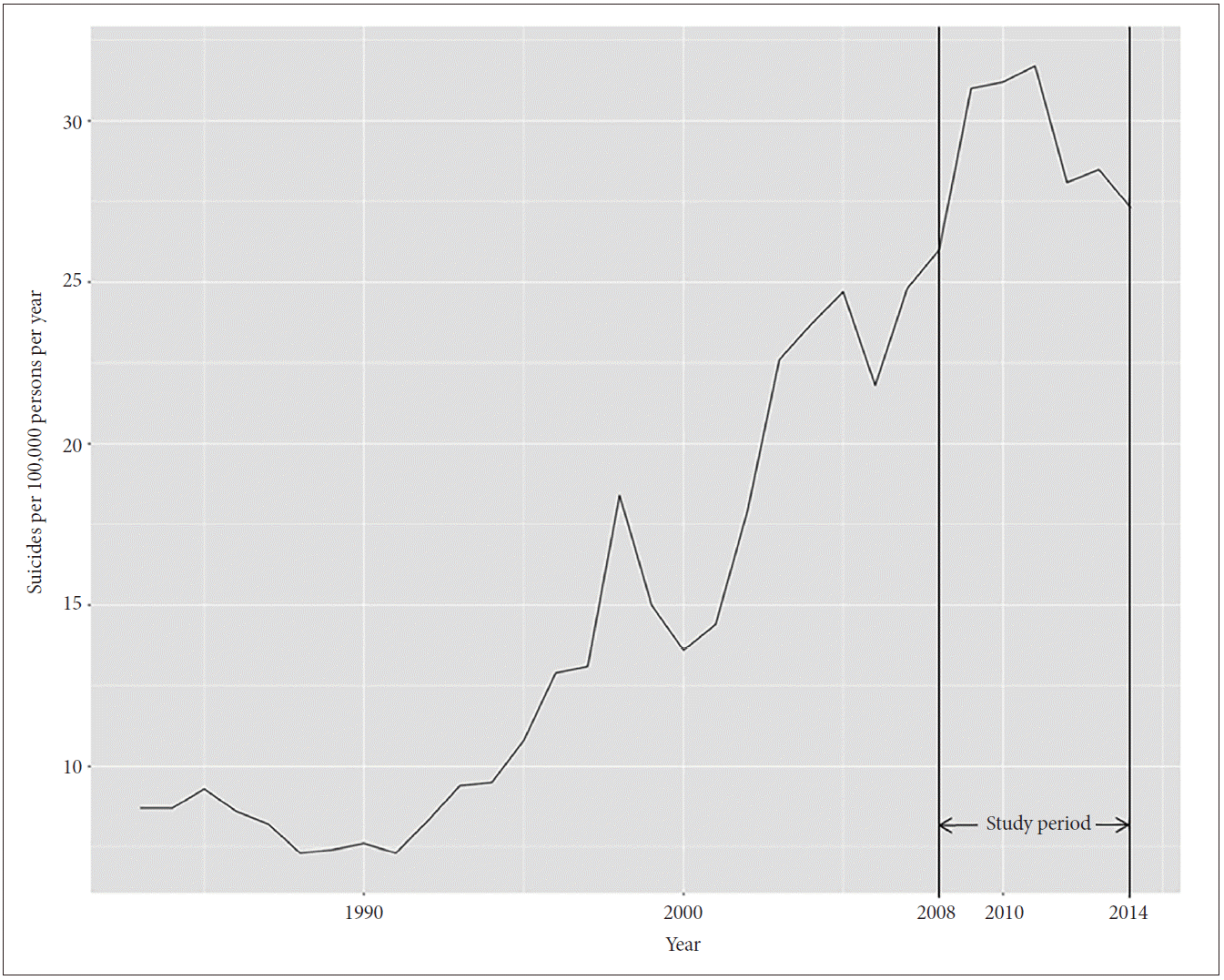
Trend of annual Korean national suicide numbers per 100,000 persons.
An example of prediction model for national suicide numbers
Our model predicted daily national suicide numbers for 2 years, using accumulated information of the preceding 5-year period for prediction modeling. For an example (Table 1), the predicted suicide number on 1 January 2013 (t) was derived from data for the unique 5-year period extending from 1 January 2008 to 25 December 2012. As the result of the stepwise AIC method selecting the best model based on the smallest AIC, 1 suicide variable, 5 of 8 economic and meteorological variables, 9 of 20 weblog counts, and 1 of 3 meaning classifications of social media variables were selected in that unique period. Through this process, the number of suicides on January 1, 2013 was predicted to be 28.75 (prediction interval: 19.60 to 40.75), and the actual number of suicides observed was 32. Among the selected predictors, the strongest single predictor of suicide number on the prediction date (t) was the suicide number on day (t-7) [log (estimates), 4.96×10-3; P, 4.61×10-16]. When expressed as percent change in relative risk, the suicide number on prediction date (t) increases by 5% (95% CI: 4.9–5.2%) per 10 additional suicide commission on day (t-7). Among the economic and meteorological variables, KOSPI and sunlight hours showed negative associations, whereas the consumer price index and celebrity suicide events showed positive associations with the observed suicide number on the prediction date (t). The log estimate of Friday effect [as the prediction date (t) was Friday] was -0.034 when the reference is Monday, but not statistically significant; People committed suicide less on Friday compared to Monday. Among the social media variables, the sum of positive words showed a negative association, while weblog counts 3, 5, 11, 15, and 20 showed positive associations with the suicide number on prediction date (t). Among 9 words of weblog counts, 3 words were related to economic aspects (Weblog count 3, 11, and 15).
Prediction variables included in 730 individual prediction models
Our model produced 730 individual daily predictions over the 2 years from 1 January 2013 to 31 December 2014. Each prediction was based on a unique set of historical data. As the prediction variables could differ at each prediction date (t), the inclusion rates of the variables showed variation over the 2 years (Table 2). There were three variables [number of suicides on day (t-7), celebrity suicide, and day of week] included in all 730 individual daily predictions, followed by KOSPI, 95.6% inclusion rate; consumer price index, 87.5% inclusion rate; and sunlight duration, 84.4% inclusion rate. Among the economic and meteorological variables, the inclusion rate for unemployment, ozone, and PM-10 was much lower (unemployment, 45.5%; ozone, 2.5%; PM-10, 0%). In Table 2 the weblog counts are listed 1–30 by rank of their inclusion rates, which ranged from 68.9% to 7.7%. Table 2 also displays the average estimates (AE) and the range of estimates for each variable across the 730 individual daily predictions. During the 2-year prediction period, we compared the predicted numbers with the observed numbers for each 730 days. As a result, of the total 730 days, 605 days of observed numbers fell within the prediction intervals with 85% probability. The prediction accuracy was 82.9%, which is defined as the percentage of correct predictions for total predictions (Figure 3). Correlation between predicted and observed suicide number was highly significant (n=730, rho=0.56, p=5.56×10-62, Spearman correlation test).
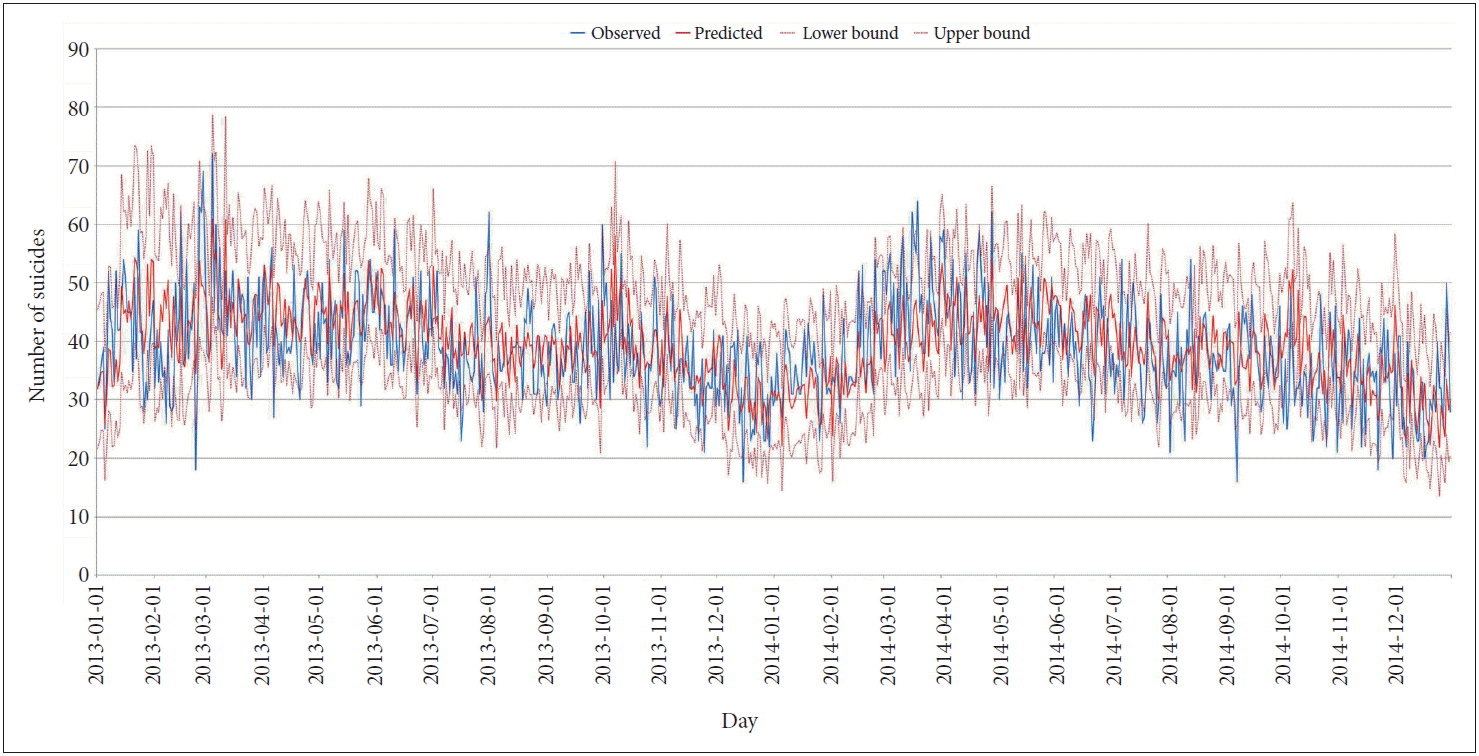
Prediction of daily Korean national suicide number in 2-year prediction period. Observed suicides (blue solid line), predicted suicides (red solid line), and prediction intervals (red dashed lines). The prediction range was computed for 85% probability. Prediction range accuracy was 82.9% for the 2-year prediction period.
The suicide number recorded on day (t-7) showed a positive association [average estimates (AE), 4.11×10-3; range of estimates (RE), 2.55×10-3 to 6.05×10-3] with the national suicide number on prediction date (t). This variable had a 100% inclusion rate. Among the economic and meteorological variables, unemployment (AE, -0.021; RE, -3.33×10-2 to -1.35×10-2), sunlight (AE, -2.17×10-3; RE, -3.34×10-3 to -1.41×10-3), temperature (AE, -1.23×10-3; RE, -1.81×10-3 to -5.47×10-4), and ozone (AE, -0.89; RE, -1.09 to -0.71) showed negative associations with national suicide numbers on prediction date (t), while the celebrity suicide variable (AE, 0.11; RE, 8.86×10-2 to 0.14) showed a positive association with national suicide numbers on the prediction date (t). For the economic variables, KOSPI (AE, 4.34×10-5; RE, -1.43×10-4 to 1.37×10-4) and consumer price index (AE, -3.79×10-3; RE, -1.48×10-2 to 1.72×10-2) showed an inconsistent direction of associations with national suicide numbers on the prediction date (t), evidenced by negative to positive values of RE (Table 2).
For social media variables classified by meaning, both positive and negative words showed negative associations with national suicide numbers on the prediction data (t), while neutral words showed a positive association (Table 2). Each of the top 30 weblog counts showed a consistently positive or consistently negative association with the observed national suicide numbers. For example, “Uuljeung” (weblog count 14, meaning ‘depressive disorder’) and “Buran” (weblog count 29, meaning ‘anxiety’) consistently showed positive associations with national suicide numbers, evidenced by positive RE values, when these words were included in the prediction models. Among the top 30 weblog counts, 18 words denoted an economic aspect (Weblog count 1, 2, 3, 6, 7, 9, 10, 11, 12, 13, 15, 18, 19, 23, 24, 27, 28, and 30); 2 words denoted mood status (Weblog count 14 and 29). Among the top 30 weblog counts, 4 words (Weblog count 2, 6, 9, and 19) showed negative associations with observed suicide numbers, while the other 26 words showed positive associations (Table 2).
DISCUSSION
The chief aim of this study is to improve the accuracy of national daily suicide rate predictions with an advanced multiple variable prediction model. Our new model predicted national daily suicide number with 82.9% accuracy, which is higher than that of the previous model we developed (79%) [12]. Additionally, a prediction time lag of 7 days was feasible and the prediction was more precisely targeted to a single day, in contrast to the 3 day-epoch of the previous model.
Several systematic reviews for suicide prevention strategies have focused principally on gatekeeper training, screening programs, public education, media education, and restricting access to lethal means [25-29]. If suicide high-risk days or periods could be predicted, various suicide prevention strategies could be optimized to reduce suicide number effectively after such vulnerable periods were declared for the population. For an example, after a famous American rock star, Kurt Cobain’s death by suicide, many experts worried that “copycat” suicide might occur in the aftermath [30-32]. The City of Seattle and several local radio stations collaborated to organize the vigil and invited a crisis clinic director to speak to the public concern and to educate thousands of mourners with the tape of Kurt Cobain’s widow presenting his suicide in a negative fashion. The press and visual media reported Cobain’s suicide and life with responsible concern, distinguishing Cobain the musician from Cobain the depressed drug abuser and suicide. These various efforts might have counteracted any potential glamorization of his death. Indeed, the record revealed no marked spike in suicides associated with the celebrity suicide [30].
Traditional approaches to suicide prevention include the use of mailings, brochures, billboards, radio, television, and telephones [33]. Over recent years, the amount of data transmitted via internet, smart devices, and social network services has exponentially increased. The internet has been widely used for suicide prevention efforts, as a means of raising public awareness and increasing access to reliable information [34]. Mobile applications on smart phones can deliver mental health interventions effectively for a range of mental health disorders, including depression, stress, anxiety, smoking cessation, and psychosis [35-37]. As the technology in electronic and ambulatory assessment devices becomes more sophisticated, mental health care would be more accessible, efficient and interactive for patients [38-41]. We expect that our improved daily national suicide prediction model could be utilized in these technologies in the near future and would assist in promoting the positive outcome of suicide prevention efforts.
It is noteworthy that among the social media variables that showed high predictive strength, nearly two thirds (18 of 30 words) were associated with economic welfare. This result might suggest that economic themes give a good reflection of public mood in social media data. This finding is consistent with multiple previous studies about the negative influence of financial stress on the suicide rate, which is observed in several countries, European Union [42], Russia [43], East/Southeast Asia [44-46], Greece [47], South Korea [48-51], and even in different continents simultaneously [52].
We also observed meaningful associations between traditional economic variables and suicide rate. KOSPI and consumer price index showed relatively high inclusion rates (95.6% for KOSPI; 87.5% for consumer price index) in the 730 prediction models. This result suggests that these variables had high predictive power for suicide and it is consistent with previous studies that linked suicide rates with the consumer price index, although the direction of the association was not always consistent [18,53,54]. However, traditional economic variables are somewhat limited in respect of immediacy of predictions, as they cannot be measured daily. Stock market variables such as KOSPI are closed 2 days a week. Consumer price index and unemployment are usually assessed periodically. Even though traditional economic variables were included in our prediction models with relatively high frequency, the majority of selected social media variables were related to economic welfare. This suggests that social media variables sampled daily might compensate for the limitations of traditional economic variables in predicting suicide numbers.
Unemployment showed a negative association with numbers of suicides, when included in our prediction models. This result is different from previous review studies which demonstrated that unemployment was positively associated with a greater incidence of suicide related behaviors [55-58] and suicide rate [12]. Sunlight and temperature showed negative associations with suicide rate, when each variable was included in our prediction models. This result does not agree with previous studies [59,60] or with our previous study [12]. Though the reason for these different results is unclear, we should note the relatively low inclusion rate of unemployment (45.5%) and temperature (54.9%) in the 730 individual prediction models. Low inclusion rates might imply that these variables had relatively low predictive strength for suicide in comparison to other variables. Therefore, the association of any single variable with suicide rate should be carefully interpreted because our prediction models included multiple variables. Negative words estimates were found to contribute to the reduction of suicide rates when included in 730 individual prediction models. However, since the negative words used in this study are classified within 10,035 candidate keywords, it is unlikely that these results represent the general relationship between the negative words used in the blog and suicide rates.
The top 30 Weblog counts of social media variables included 2 words meaning ‘depressive disorder’ and ’anxiety’ in the prediction models. This result might imply that public mood was sensitively represented by social media data. There have been several studies that suggest social media data could be used to detect public mood sensitively [61-64]. In our previous study, two weblog words denoting ‘suicide’ and ‘dysphoria’ were significantly associated with national suicide number [12]. Jashinsky et al. [11] used suicide-related keywords and phrases on tweets which included depression and other psychological disorders for study. They found a strong correlation between regional Twitter-derived data and observed regional suicide data.
In conclusion, our prediction models could predict national suicide number for a single date 7 days in advance with 82.9% accuracy, which is an improvement on our previous study [12]. Overall the correlation between predicted and observed daily suicide rates was highly significant, accounting for 31% of the variance (r=0.56) over a 2-year span of daily predictions. Considering that the data used for these predictions cannot account for subject-specific variables, the correlation between predicted and observed daily suicide numbers is encouraging. When used in combination with traditional economic variables, the social media data, especially words related to economic welfare or mood status, showed high predictive strength. Further studies for utilization of this model to advanced technology are needed.
Acknowledgements
This research was supported by a grant of The Korea Health Technology R&D project through The Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (HI13C1590).