INTRODUCTION
Suicide has been a major public health problem in Korea, which took second place in the suicide rate (25.8 per 100,000 population) among the OECD countries in 2016. Suicide is a complex sequential process including ideation, planning, and attempt leading to the final completion [1]; approximately one-fifth of individuals who think about suicide might eventually attempt suicide [2]. Specifically, progression from SI to suicidal attempt could be facilitated when an individual suffers from poor impulse control or poor mental health [3,4]. Of note, possible aggravating factors that contribute to suicidal ideation (SI) may include depression, loneliness in human relationships, economic difficulties, or physical pain [5]. Accordingly, attentive questioning for suffer from the suicidal ideation in the primary outpatient clinic, followed by timely consultation to the psychiatrists, could be crucial for effective reduction of suicidal risks for community population [6]. However, studies to elucidate the primal risk factors of SI for individuals visiting the primary outpatient clinic with issues other than the SI have not been sufficiently conducted yet [7-11].
As one of the efforts to overcome the issue of generalizability for the study results per sites and to enable more valid application of study results at individual level, big data analytics combined with the machine learning methods also have been adapted in the field of medical science. Predictive big data analytics refers to the use of algorithms, systems, and tools to extract information, generate maps, prognosticate trends, and identify patterns in a variety of past, present, or future settings [12]. With the recent advancements in technology and data science [13], artificial intelligence using machine learning methods is utilized widely in medicine to predict the prevalence of various diseases or therapeutic outcomes [14]. These machine learning methods have shown better performance in predicting unmeasured outcomes as compared to conventional statistical methods [15,16]. For suicidal risks in association with psychological variables, previous history of suicidal attempts [17], current suicidal ideation [18], upcoming suicidal attempts [19] as well as the subtypes of longitudinal trajectories in changes of depressive symptoms and suicidal ideation [20] have been classified by way of the machine learning methods that applied several psychological symptoms including depressive mood, family- and pharmacotherapy-related features as explanatory features. On the other hand, few previous machine learning method-based big data studies have explored the risk factors of suicidality from the non-psychological variables to be prioritized in the primary care clinic [21].
Therefore, the present study aimed to establish models to predict the risk of SI among Korean adults using a machine learning approach. We analyzed a large dataset of a representative Korean population to identify the factors associated with SI and to validate the performance of different machine-learning models to predict SI. To our knowledge, this is one of the largest studies to apply machine learning algorithms to identify risk factors and to build prediction models for SI ever performed.
METHODS
Data source: the Korea National Health and Nutrition Examination Survey
The dataset used in this study was acquired from the fifth and sixth Korea National Health and Nutrition Examination Survey (KNHANES) which is a nationally representative annual health survey conducted in Korea on the health and nutritional status of the general population [22]. The KNHANES is conducted by the Ministry of Health and Welfare of Korea under the leadership of the Korea Center for Disease Control. The fifth and sixth KNHANES were performed from 2010 to 2012, and 2013 through 2015, respectively. In 2014, SI was investigated only for adolescents and not for adults, and thus the 2014 KNHANES dataset was excluded from this study.
The details of the KNHANES are described elsewhere [23]. Briefly, this annual survey extracted 4,000 households nationwide, using a stratified multi-stage clustered complex sampling method based on age, sex, and area of residence. The selected participants were interviewed regarding their health and nutritional status. Adults aged ≥19 years were asked to answer a questionnaire regarding SI, suicide planning, and suicide attempts. The participation flowchart has been presented in Figure 1. The survey adhered to the tenets of the Declaration of Helsinki. Written informed consent was acquired from all participants. The KNHANES survey protocol was approved by the Korea Center for Disease Control Institutional Review Board (IRB no. 2010-02CON-21-C, 2011-02CON-06-C, 2012-01EXP-01-2C, 2013-07CON-03-4C, and 2013-12EXP-03-5C). Since 2014, the KNHANES has been exempted from review for research ethics, based on the Bioethics and Safety Act.
Measurement of main outcomes
Assessment of suicidal ideation
Two suicide-associated variables were investigated using self-reported health questionnaires, SI and actual suicide attempts. SI was assessed using the following question: “Have you seriously thought about wanting to die during the last one year?,” to which the participants responded using “Yes” or “No” responses.
Assessment of independent variables
The KNHANES assessed over 800 variables on various aspects of the health and nutritional status of participants. Therefore, to reduce the high dimensionality of variables, before conducting the present analyses, a psychiatrist (JYY) carefully reviewed all variables included in the survey and selected candidate variables potentially associated with SI. Variables regarding suicide attempts were excluded from the study because they were directly associated with SI. Based on the consensus between a psychiatrist (JYY) and family medicine physician (BJO), 48 candidate variables were selected. Primarily, the chosen variables included participants’ demographics, anthropometric features, socioeconomic status, lifestyle or health behavior variables, and systemic health conditions, including comorbidities and blood analysis results.
Demographic characteristics included age, sex, residency, marital status, and educational status. Socioeconomic variables such as occupation, personal monthly income adjusted for the number of family members, and family income were also included. Anthropometric variables included height, waist circumference, and body mass index (BMI). Health behavior factors included drinking habit, smoking, physical activity, and mental health related items such as stress and depression. High-risk alcohol consumption was defined as drinking ≥7 glasses of alcohol for men or ≥5 glasses of alcohol for women on one drinking day [24]. Alcohol dependence was evaluated using the score on the 10-item Alcohol Use Disorder Identification Test (AUDIT) [25]. Physical activity was evaluated in terms of engaging in strength or flexibility exercise one or more days per week.
Stress awareness was classified into the following 4 grades: 1, very much; 2, much; 3, less; 4, rarely. Depression was determined based on whether they have felt sad or desperate continuously for ≥2 weeks during last year. Systemic comorbidities for common diseases such as hypertension, diabetes mellitus (DM), depressive disorder, or cancer were also investigated. Blood test results for complete blood count, liver function, kidney function, and coagulation panel were included.
Data analysis
Building training and testing datasets
Before constructing the training and test datasets, the whole dataset was examined for missing data. Participants who had any missing value for independent variables or SI assessment were all excluded from the study. Next, the 2010-2013 and 2015 KNHANES datasets were divided into the following mutually exclusive sub-datasets: the training dataset and the test dataset. The 2010-2013 KNHANES dataset was used as the training dataset, and the 2015 KNHANES dataset was used as the test dataset to evaluate the final performance of different machine learning models that were built using the training dataset. Preprocessing of data and development of machine learning models were performed using the Weka software (Waikato Environment for Knowledge Analysis, version 3.8.1., University of Waikato, New Zealand) and R version 3.6.2 (the R Foundation for Statistical Computing, Vienna, Austria).
The training and test datasets were unbalanced for the target outcome SI because the proportion of participants reporting SI was around 10% in each year. As a classification bias arising from data imbalance was expected [26], the training dataset was re-balanced in terms of SI endowing calculated weights that made the SI and non-SI groups equal. The ClassBalancer function in the Weka software, a supervised instance filter, was used for this purpose. As a balancing method, down-sampling for the majority class may be an option, but it has the disadvantage of losing data of the majority class. Over-sampling replicates the copies of the minority class, or adds more weight to the minority class. The ClassBlancer method might be similar to over-sampling in the context of adjusting learning weight and not losing the data of the majority class. In contrast, the testing dataset was not re-balanced and was used in its original form. Data normalization was done for numerical data of the training and test datasets, rescaling the features to the rage of 0 to 1.
Feature selection
To build machine learning models, feature selection was performed using the wrapper-based feature subset evaluation method in Weka. The best-first search method with forward selection, the area under the receiver-operating characteristic (ROC) curve as a performance measure, 5-fold cross-validation, and the seed value of 1 were selected. We adopted the Bayesian network (BN), LogitBoost with logistic regression (LB), support vector machine (SVM), decision tree (DT) of J48, and artificial neural network (ANN) using multilayer perceptron algorithms in Weka. SVM was trained using the sequential minimal optimization algorithm with a linear polynomial kernel. ANN was used as a multilayer perceptron with 3 hidden layers and a learning rate of 0.01, which is a feedforward ANN. For each algorithm, a feature subset maximizing the area under the ROC curve (AUC) of the algorithm was obtained. Additionally, we used a logistic regression (LR)-based model as a reference conventional statistical method [15,27]. For this model, the backward stepwise elimination method with Akaike Information Criterion was adopted to select associated variables using the R software. The optimal cutoff point in the ROC curve was determined using the Epi package in the R software.
Construction of machine learning models
After obtaining an optimal feature subset for each algorithm, sub-datasets were created for each machine learning algorithm from the training dataset, including only the optimal feature subsets. With each training sub-dataset BN, LB, SVM, DT, and ANN machine learning models were constructed. For each algorithm, the model maximizing the AUC was adopted.
Performance evaluation
The prediction models were evaluated using the testing set. The performance of each models was compared with the others using AUC. The prediction accuracy for SI, sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) were also calculated.
RESULTS
Characteristics of the participants
Among the eligible 51,214 participants, 40,932 participated in the health examination and answered the questionnaire in the 2010-2013 and 2015 KNHANES (79.9% response rate). Ultimately, 16,437 participants aged ≥19 years were included in the training dataset. The test dataset comprised 3,788 cases. The demographic characteristics of the participants have been presented in Table 1. Participants who reported the presence of SI tended to be older, female, and in worse economic and educational status (p<0.001 for all) as compared to those in the non-SI group. Additionally, those with SI had higher AUDIT scores; lesser frequency of physical exercise; poor subjective health status; and higher prevalence of systemic hypertension, stroke, diabetes mellitus, renal failure, liver cirrhosis, depressive disorder, and injury within the past 1 year.
The prevalence of SI was 11.9% (1,957 of 16,437) in the training set consisted of the 2010-2013 KNHANES datasets. On the other hand, the prevalence of SI was 5.5% (210 of 3,788) in the 2015 KNHANES dataset used as the test dataset in this study.
Selected features from the machine learning models
The features selected to build a prediction model by the wrapper-based evaluation for each algorithm have been presented in Table 2. Each algorithm adopted 6 to 21 features to construct the predictive model. Decision tree algorithm selected the least number (n=6) of features and LB extracted the greatest number (n=20) of associated features which is about twice as the number of features selected in the conventional LR model (n=11).
The common variables selected unanimously in all the models were the presence of depressive disorder, stress awareness, continuous depressive mood lasting ≥2 weeks, and Euro-QoL-5D (EQ-5D) score. Household income, sex, unmet medical service needs, and AUDIT score were adopted by five algorithms except one.
Predictive performance of the machine learning models
The performance metrics of the models for the prediction of SI have been presented in Table 3. The conventional logistic regression analysis showed an AUC of 0.867. Prediction sensitivity and specificity were 79.0% and 78.5%, respectively. Of the machine learning models, the LB and ANN models showed the best performance on predicting the presence of SI (AUC, 0.877). The sensitivity of the LB model was 81.0% and its specificity was 78.7%. Otherwise, the BN model showed a similar AUC compared to the LR model (AUC, 0.867).
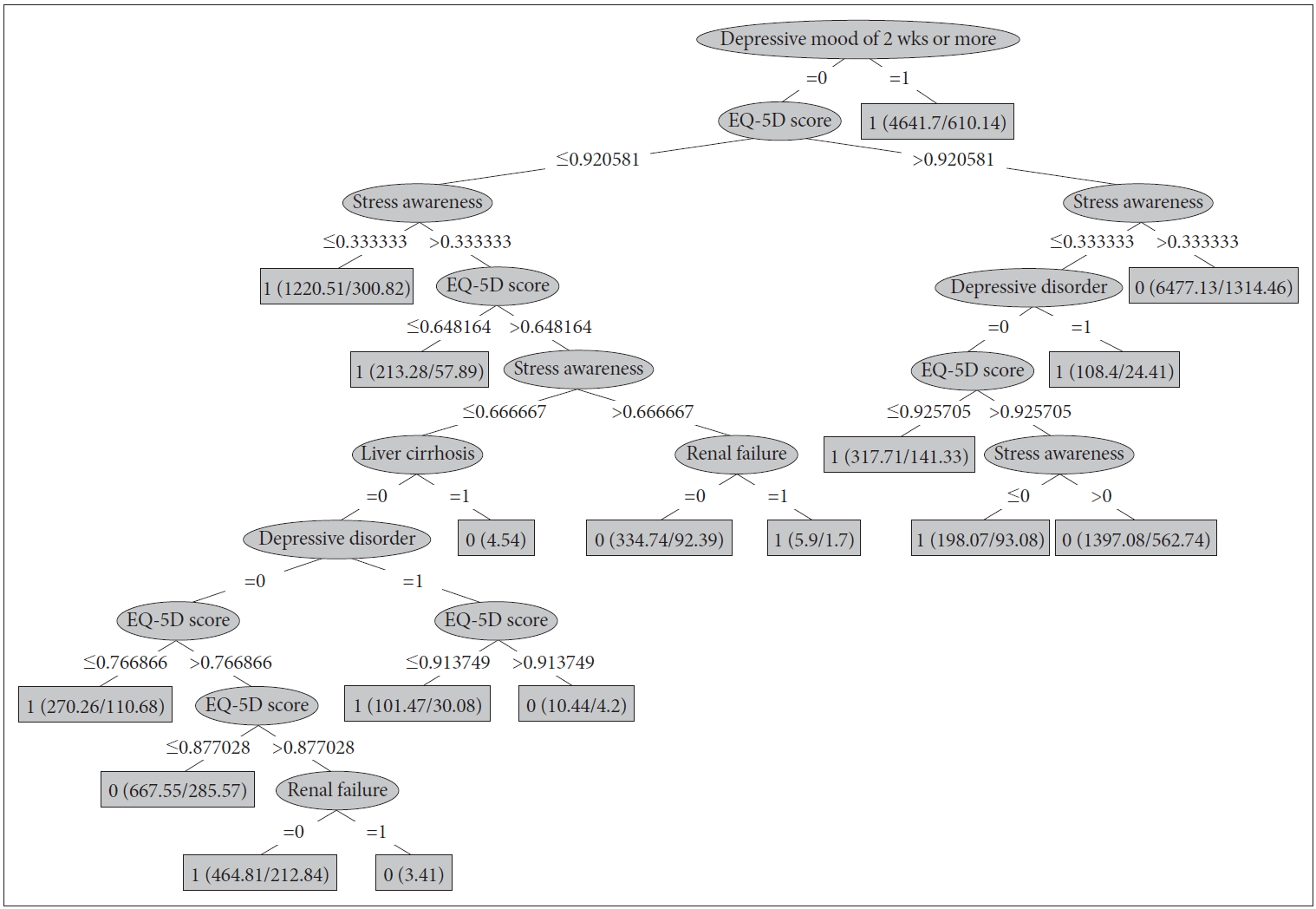
Figure 2 shows the decision tree suggested by the DT algorithm. The determinant at the highest branch was continuous depressive mood lasting ≥2 weeks; 88.4% of the subjects with this feature had SI. The determinants in the following steps included EQ-5D score, stress awareness, and the presence of depressive disorder, respectively.
DISCUSSION
The present study investigated the health-related risk factors for SI in Korean adults applying machine learning algorithms to the nationally representative KNHANES data. Common risk factors useful for recognizing the SI in all the machine learning models were stress awareness, sustained depressive mood more than 2 weeks, and quality of life associated with general health status (EQ-5D score). In addition, the prevalence of depressive disorder, status of household income, sex, unmet medical service needs, and alcohol use problem (AUDIT score) were adopted by five machine learning models developed in the current study. The current study showed a better performance compared to previous machine-learning based studies, reaching an AUC of 0.877.
Depressive mood: a risk factor and possible mediator between demographic/physical health-related factors and SI
Our results suggest that the experience of continuous depressive mood is a common risk factor for SI in all models and that depressive disorder appears as a significant risk factor in most of the models. These results are in accordance with previous studies that suggested depression is significantly associated with SI, showing an increased suicidal risk as high as 3.73 times in the elderly population with comorbid depressive disorder or 2.17 times in the university students with depressive symptom, as compared to those without [28,29]. Public psychoeducational programs for depression have been found effective in reducing the incidence of suicide attempts [30-32].
In terms of the mediating factors between these demographic or physical health-related variables, stress cognition, and depressive mood have been identified as some of the most influential factors in SI. Previous researches have reported that various demographic risk factors increase suicidality, including older age [33], being an unmarried male [34], and having lower economic status [35]. In a meta-analysis, alcohol abuse was also reported as a significant risk factor for SI [odds ratio (OR)=1.86] as well as for suicide attempts and completed suicide [36]. In addition, poor health-related quality of life has also been associated with SI or suicidal behavior in many studies [37,38]. Physical illness and functional disability were other factors associated with suicide [39]. Similarly, the various machine learning algorithms adopted in the current study, including SVM, ANN, and BN, disclosed several risk factors that were reported in previous studies. Although some variables, such as smoking or physical exercise, were determined as risk factors only in part of the algorithms, the risk factors identified in this study could provide medical explanations in terms of the association of these variables with SI.
Better performance in recognizing the SI compared to other machine learning studies
The current study included the general population regardless of the mood status, but showed a better performance compared to previous machine-learning based studies, reaching an AUC of 0.877. Thus far, many studies have tried to predict the risk of SI using various methods. In the American general population with depressive mood, a prediction model using logistic regression showed an AUC of 0.809 (95% CI, 0.779-0.840) in the validation dataset [40]. Specifically, Liu et al. [41] modified the conventional logistic regression method by shrinking the coefficients with heuristics, to prevent the overfitting of the model and to improve model performance. In another study, a prediction model for SI was built using about 15 variables in Chinese patients with depression [42]. Specifically, Fang et al. [42] used a stepwise logistic regression analysis and the AUC of the model was 0.80 (95% CI, 0.78-0.81), which was lower than that observed in the present study.
The superior performance achieved in the current study for recognizing the presence of SI in general population might be attributed to larger number of input variables or different algorithms of the machine learning-based approach, and to the large sample size. Most of the machine learning algorithms tested in our study showed performances comparable to that of the LR-based model, using fewer variables. On the contrary, the tested machine learning algorithms did not surpass the performance of the simple LR-based model. The reason for this is not clear thus far, but the association of risk factors, such as the EQ-5D score or the presence of continuous depressive mood with SI, could have a sigmoid-like pattern, thus leading to the better performance of the LR-based model. Collectively, simpler models built by machine learning algorithms may help to understand the risk factors for SI more clearly, and they may aid the evaluation of the SI risk of an individual more easily.
Study implication: how to recognize the patients with higher risks of SI at primary medical institutions
Considering the under-diagnosis of SI in primary care settings and the low rate of consultation with psychiatrists [43], the present study might help primary care physicians to identify individuals who are at a higher risk of SI and to initiate timely co-working with psychiatrists [44]. A previous study found that those who had attempted suicide had more than twice the rate of visiting non-mental health facilities before such an attempt [45]. This can be interpreted as the social prejudice against psychiatric illness and treatment, rather than as a cause of depression and suicidal thoughts. Therefore, the screening and intervention of suicidal risk at primary medical institutions may be very important for patients with or without depressive disorder. Active interactions with patients requiring mental health care services and removing trigger factors for suicidal behavior are also important. As shown in the present study, interventions for smoking cessation and physical exercise related health education, and reducing stress and depression could be helpful for preventing suicide among elderly individuals.
Study limitations
This study has some limitations that need to be considered. First, this study used one question to evaluate SI that required the participants to respond as “yes” or “no” to indicate its “presence” or “absence.” The related paucity of more quantitative data about the severity of SI might have restricted a more detailed evaluation of the validity and reliability of the predictive models developed in this study. Second, the measurement of SI through a self-report questionnaire was not accompanied by a more facilitative clinical interview with a clinician (as in the database used in this study). This may have led to higher chances of false-negative predictions of SI. Third, there was a discrepancy for the prevalence of SI in the training dataset and the test dataset. The lower prevalence of the minority class in the test dataset might have increased the performance of machine-learning algorithms. Fourth, direct comparison for the prediction performance using the AUC value between LR and other machine learning models may not be appropriate because machine learning models were developed using the Weka, while the LR model was developed using the R software. However, considering the amount of time that would be required to acquire this massive amount of data through face-to-face interviews, the strategy of using the KNHANES data—a nationwide representative survey of the adult population in South Korea—could have been a more favorable option.
Conclusions
The current study demonstrated the clinical utility of the machine learning approach in providing performance for SI prediction that was comparable to that of the conventional LR-based model. Our machine learning-based predictive models for SI might help primary care physicians to identify patients at a higher risk of experiencing SI, thereby facilitating the early and active implementation of preventive interventions, including psychiatric consultation and modification of suicidal risk-related medical conditions. The present results might be helpful in designing and implementing suicide prevention programs effectively.